
The Softalk magazines are brimming with "facts" about the Microcomputer Revolution. This overview will tell you a bit about how we will use graph database technology to unlock this incredible resource within our 9,100-page treasure trove.
The core data modeling constructs of a graph database are "nodes" and "relationships." I could tell you more, but this short four-slide explanation on the Neo4j website nails it. (Neo4j is the Open Source graph database from Neo Technology that we will be using for this project and for the Fact Miners social game app platform.)
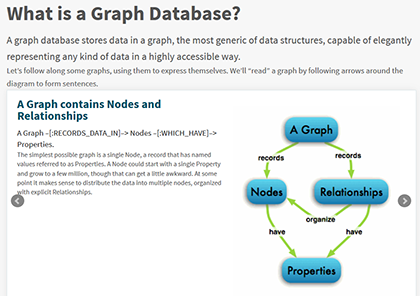
The graph database's [NODE] => [RELATIONSHIP] => [NODE] construct can be used to create a flexible "grammar" that both organizes known information AND provides the flexibility to organically evolve your information model as new information is discovered and we expand our understanding of interrelationships within our data. In short, a graph database is ideal for creating The Softalk Apple Project "Fact Cloud" Companion.
Let's take a look at one simple example: "Choplifter is the #1 bestseller on the Top Thirty list in the October 1982 issue of Softalk."
We start with this elementary structure:
![An elementary graph DB 'fact' - [Node] => [Relationship] => [Node]](sites/default/files/FactCloud_1.png)
With this simple construct, we can express "facts" (elementary assertions) such as:
- ["Joe"] => ["Likes"] => ["Jane"]
- ["The sky"] => ["Is_color"] => ["blue"]
- ["Acme Inc."] => ["Makes"] => ["Widgets"]
Simple, powerful... but you can see where things would get gnarly quickly if everything had to be expressed, stored, and retrieved at such a fine-grained level. So, beyond this core construct, a graph database (like Neo4j) can allow labels and property lists to be attached to Nodes and Relationships providing additional "flavors" of expression within our data model:
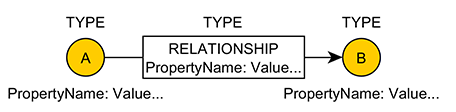
These label and property-list "decorations" dramatically enhance the range of what can be expressed in the information model of a graph database – a "fast bike" rather than a "bike" which can itself be labeled as a type of "vehicle." Before we quickly get beyond the "wee bit" focus of this page, let's look at how we can use this notation to "gather the facts" that we know from this one line in the Top Thirty list in the October 1982 issue...
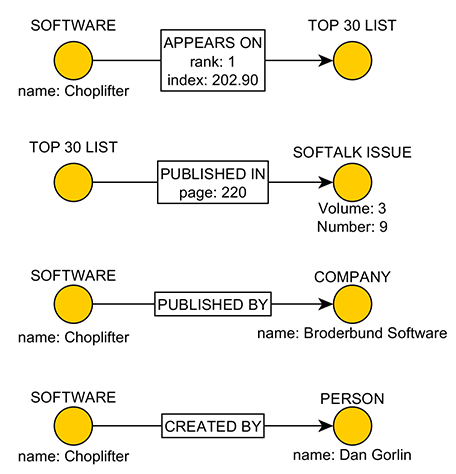
If we put these elementary "facts" together in a connected graph, you see the start of a "Fact Cloud"...
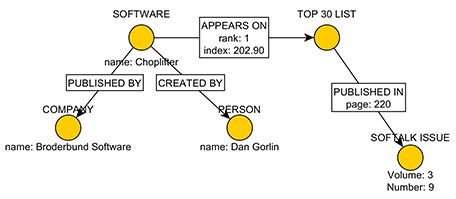
Now imagine a voracious social game-playing community of "Fact Miners" descending on The Softalk Apple Archive. Imagine how many "facts" this crowdsource resource could find on a single page of the magazine. Extrapolate that out to a full issue, then imagine if all 9,100+ pages of the 48 issues of Softalk were mined for their embedded facts. Imagine what an unprecedented education and research resource could be created by a bunch of folks having some "serious fun."
This is our vision for the Softalk Apple Archive "Fact Cloud Companion" that we will create through this project and its "spawn" of the www.FactMiners.com social-game community and the www.FactMiners.org developer community.
(You may want to hop back to the About page...)
Comments
Types of relationships between nodes
Can you share any general guidelines about how to structure (or think about) relationships between nodes, either for graph DBs in general or for this project in particular? I can foresee people jumping in excitedly to do the fact-mining and coming up with variations on the properties of any given relationship type, which could cause confusion and/or redundancy down the line.
Are there generally valuable properties (page number, volume number, rank, author, color [as contrasted with b/w], editorial [as contrasted with opinion/advertising/letters/puzzle/etc.]) that one might look to assign to any given relationship?
The whole idea of graph DBs is new to me, though it somehow oddly reminds me of mapping out Infocom adventures way back when...but I think any organizational or conceptual structure we can provide up front could save the mappers a great deal of time and effort later on.
...jg
John Gruver
A+ :-) Perfect question, John
For a quick placeholder reply let me say that your perceptive question has a very specific answer. But I will have to stop for the moment at the "solution identification" level of response and we'll get to the "how this works" level in a follow up (which I will pop back here and point to when it comes on-line).
So the quick and incomplete answer is that a FactMiners Fact Cloud graph database will be "seeded" with a sub-graph (an initial collection of nodes and relationships) that serve as a "self-descriptive profile" that is used to answer exactly the kind of questions you've alluded to such as "Where am I?", "What kind of things are we interested in here?", "What can I say about this type of thing?", "How can this type of thing be related to that type of thing?", "Does this Fact Cloud allow me to add new Things or Relationships?" etc.
In other words, the API (Application Programming Interface) for a "self-descriptive" Fact Cloud will support the client-server conversation that will seamlessly configure the FactMiners device app (the client) for "serious play" on whatever Fact Cloud host repository (sever) the FactMiner gamer hooks up to through the FactMiners.com catalog of available Fact Clouds.
Without going further at the moment, I can tell you that this is EXACTLY the design issue that we'll be tackling in the next GraphGist Domain Modeling Contest sponsored by Neo Technology, the folks behind the Open Source Neo4j graph database we'll be using the FactMiners back-end. Needless to say, all this goes beyond the scope of a response here, but THANKS and "Spot on!" for asking such excellent questions.
In the meantime, if you want to see a GraphGist that explores the subject of "self-descriptive" graph databases, I am happy to point you to this EXCELLENT submission by Curt Gardner to the September domain modeling contest; 'A Simple Meta-Data Model for a Graph Database'. More as it unfolds... :-)