First, let me admit that IANAMIP – I Am Not A Museum Informatics Professional – so forgive me for what I don't know. My purpose with this article is to engage the interest of any reader who may be a member of the museum informatics community, not to alienate you by presuming to speak with any authority or direct experience. I also want to introduce our informal 'Friends of Softalk' community to what is admittedly an esoteric aspect of our project. Regardless of what motivates your reading, I welcome all feedback and comments. And on behalf of our project, we welcome the active interest of, and potential collaboration with, members of the museum informatics community.
About The Softalk Apple Project and Our FactMiners.com/.org Initiative








As part of our project's mission, we are developing the "FactMiners ecosystem." This ecosystem once realized will consist of:
- the FactMiners multi-platform social game app
- www.FactMiners.com – the web service providing gamification, player community, and repository workflow infrastructure
- www.FactMiners.org – the Open Source developer community to create and expand the FactMiners game app, server-based web services, and repository APIs, etc.
- "Fact Cloud" repositories – the first being the Fact Cloud to be developed and hosted by The Softalk Apple Project
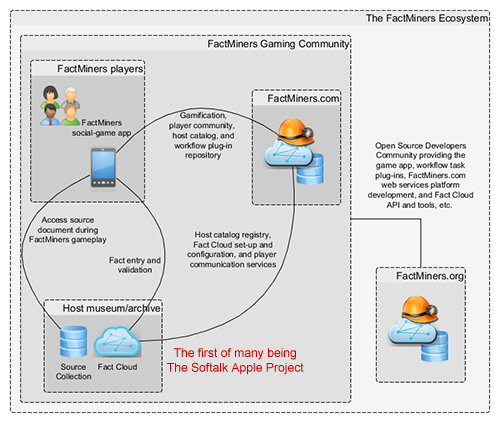
Our goal is to create a crowdsource-powered social gaming community that "comes to play" in museum and archive on-line repositories with the intensity of the multitudes who play Candy Crush or Words With Friends. And by playing FactMiners, this rabid game-playing community will produce two results:
- Players will spend time exploratory-learning about whatever is the content of a host collection, and
- The host museum or archive will get a Fact Cloud data repository [1] that will become increasingly valuable as an educational and research resource.
In short, both the means – FactMiner exploratory-learning game-playing – and the ends – the "by-product" generation of the host collection's Fact Cloud – have value in their own right.
[1] See A Wee Bit about Graph DBs and Fact Mining
Isn't FactMiners just Folksonomy (Social Tagging) in a Game Wrapper?
The closest thing to FactMiners that I know about within the museum informatics community – please note I have an admittedly limited knowledge in this regard and welcome feedback to broaden my perspective – is the brilliant work being done on folksonomy which Wikipedia summarizes as:
"A folksonomy is a system of classification derived from the practice and method of collaboratively creating and managing tags to annotate and categorize content; this practice is also known as collaborative tagging, social classification, social indexing, and social tagging." (http://en.wikipedia.org/wiki/Folksonomy)
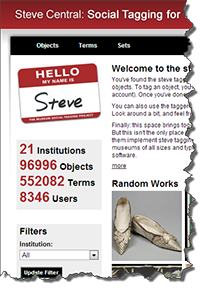
The folksonomy/social-tagging community has produced impressive results through such collaborations as the steve project which now includes 21 institutions (museums and archives) whose over eight thousand community members have tagged nearly 100,000 objects with over half a million terms. Another great example is the Virtual Museum of the Pacific, a creative collaboration of the Australia Museum and Wollongong University researchers.
This is truly impressive work. But I believe Fact-Mining, while related and complementary, is qualitatively different than social-tagging. This said, we certainly know that we will learn from the folksonomy folks' experience and welcome the opportunity to collaborate with those working in this domain.
Beyond Folksonomy for Serial Magazines
Many museum and archive collections are well served by folksonomy's focus on classification coupled with collecting community members' insights, stories, and fragile memories captured for posterity.
However, while relevant at one level of artifact description, property-based classification may be insufficient for the subset of collections that include such artifacts as serial magazines and newspapers. While the physical artifact can be richly described through attribute categorization, these physical item properties do not help us if we want to identify and explore the information content expressed in the text and graphics of a magazine or newspaper.
Serial magazines – especially those like Softalk with a very specific editorial focus – are a unique resource. Taken collectively throughout a publication's run, serial magazines produce a sequence of "time capsule snapshots" of what's going within the domain of the publication's editorial focus.
"Fact mining" (by FactMiners) is intended to be a fun and educational way to unlock the "facts" contained in these collections such as magazines and newspapers. (As an aside, don't take "fact" too literally. Assertion is a more accurate term as a "fact," in our sense, need only be verifiable as having been stated/asserted in the source document.)
The goal of creating a "Fact Cloud" is to find, capture, and verify (that is, to "mine") the information content from its source document human-readable format into a machine-queriable data format.
Magazines as a Rich Data Source

A magazine – while a fun and lively source of information and entertainment if all we want to do is read it – is actually a quite complex document when we take into account both its content information model and its document structure.
On the content modeling side of things, a magazine like Softalk is about People, Companies, Hardware (Products), Software (Products), User/Consumer Stories, Market Information, Product Reviews, Sales Performance (e.g. Softalk Bestseller Lists), etc.
These types of "Things" may be the subject of "facts" that either connect Thing-RELATED_TO->Thing or Thing->HAS_ATTRIBUTE->Property, etc. Such relatively simple Thing->RELATIONSHIP->Thing expressions can be conditionally combined into semantically rich data/information models. (This topic is beyond the scope of this article. For a bit more see this short piece about graph databases and FactMiners.)
A magazine has an additional layer of information structure; Feature Stories, Columns, Editorials, Advertisements, Polls, Reader Contests, Bestseller Lists, Letters to the Editor, etc. The magazine's structural nature complicates the scanning and OCR (optical character recognition) requirements when putting a magazine collection on-line. In order to "fact mine" a magazine, we have to capture and organize our facts respecting the magazine's document structure. It is important, for example, to know which fact assertions are derived from advertising copy as opposed to the same assertion coming from an article, featured column, or product review.
When both the content information and magazine structural aspects are captured in the Fact Cloud of a serial magazine, we get a very interesting time-series dataset that can be used to "see" social and market dynamics which cannot be gleaned by simple piecemeal reading of preserved issues in these on-line collections.
The Fact Cloud as Education and Research Resource
Once an army of FactMiners' game-players "consume" a museum or archive host's source repository and leave the by-product of the Fact Cloud representation of the collection's source material, the host institution will have a qualitatively different and important new resource for both education and research.
Given a set of analytic query tools for aggregation and visualization – as will be part of the mission of FactMiners.org, the Open Source developer community supporting the FactMiners ecosystem – it is easy to imagine how this resource would enhance casual visitors' exploratory learning experiences.
But perhaps the greatest value will come from the increased efficiency that a Fact Cloud can provide to serious researchers. Given access and tools to use a sufficiently comprehensive Fact Cloud, prospective researchers may be able to significantly reduce or even eliminate the need for ad hoc ("one-off") data gathering and scoring tasks within a research project. Indeed, a Fact Cloud may very well enable researchers to imagine and then pursue answers to questions that they might not have even asked before availability of a Fact Cloud companion to a source collection, especially when faced with limited research funding.
I could go on speculating about the prospective value of FactMiners' Fact Clouds as educational and research resources, but in closing I want to turn to an underlying question...
Won't FactMiners Fail Like John Henry?

One might suppose that my comparison of FactMiners with folksonomy begs the question of whether a crowdsource-powered social gaming approach to text mining (the more general domain of FactMiners, AKA text analytics) can realistically compete with the sophisticated technologies for algorithmic knowledge graph and ontology generation, concept and entity discovery, etc. found in the emerging market for enterprise-based semantic web solutions offered by such players as Digirati, Bitext, and The Semantic Web Company.
In other words, isn't FactMiners' fact mining doomed to the same fate as John Henry who pitted his prowess as a "steel-drivin' man" against the steam-powered hammer of industrial mechanization?
In answer to this important question I believe my sentiments would align more closely with those in the museum informatics community rather than the players in these enterprise markets. That is, while I see the importance and need for computational/machine solutions to text mining for domains such as health care records management and research, social media marketing, recommendation-based publishing, and government services (among others), we cannot lose sight of one of the fundamental goals of organizations that preserve and make available on-line collections and archives such as The Softalk Apple Project. And that is, our mission is driven by a commitment to encourage access to our collections within an exploratory learning environment; to be the spark that ignites new interests and understanding.
We simply cannot outsource to machine algorithms the exercise of our minds and the value of learning from our past. So on one level, the question of whether we could do FactMiners "better, faster, cheaper" with emerging text mining and text analytic technologies is moot. But let's be clear. This is not a distinct either/or proposition.
There is plenty of room for judiciously incorporating emerging relevant technologies into the FactMiners ecosystem. The cutting edge will have to be "Does this addition make playing FactMiners more fun? Does this make it a better game?" And there is nothing about fun that can't incorporate increased efficiency or ease of guided user interaction.
For example, the www.FactMiners.org developer community mission will include an initiative to promote development of "machine-assisted" FactMiners' fact mining. We foresee this Open Source community sponsoring academic and independent developer contests to contribute "smart plug-ins" to the mix of task-engine workflow resources available to FactMiners' players.
We expect to see "machine-assists" for efficient fact discovery, composition, and verification, but their use will not be mandatory nor will they encourage "machine cheating" within the scoring and achievement aspects of the social game. There will be gamification dynamics/constraints in place to ensure that "human only" FactMiners players do not compete at a disadvantage with "machine-assisted" FactMiners.
To support Fact Cloud hosts' visitor engagement goals, the Fact Cloud configuration profile will include a setting in the API to allow or disallow players' user of "machine-assisted" workflow plug-ins when contributing to the organization's Fact Cloud. And we plan to host John-Henry-like "Human vs. Machine-assisted" friendly team tournaments as well as maintain separate leader-boards and achievements for Manual and Machine-assisted play.
I could go on in speculation about what will be in or out in terms of FactMiners fact mining, but this is already an overly long piece by web-reading standards. (Thank you for getting here, BTW.) My hope is that I have said enough, and said it clearly enough, to accomplish our original goal of writing this piece. And that is...
We welcome members of the Museum Informatics community to help us in our mission to preserve, explore, and extend the legacy of Softalk magazine. And in doing so you will help us contribute the FactMiners ecosystem to the resources available to museums and archives hosting on-line collections.
The Softalk Apple Project
Cedar Rapids, Iowa USA
Recent comments